File Explorer
1/2025 - 3/2025
Individual project for CSE 333 Systems Programming course, linking a web server to an inverted index of a file directory
Written by: Violet Monserate
Key Tools
In order to ensure that my code was working, I utilized 2 debugging tools:
- GDB: This allowed me to go instruction by instruction and inspect the state of the program, which was especially useful when tracking “segfaults”
- Valgrind: This allowed me to see how memory was being utilized by our program, and ensure that we were allocating and freeing memory correctly.
Homework 1: C Data Structures Implementation
Overview
Implemented two fundamental C data structures from scratch:
- Doubly-linked list with iterator support
- Chained hash table with dynamic resizing
Key Features
- Generic payload support for storing arbitrary data types
- Memory management with proper malloc/free handling
- Iterator abstractions for safe data structure traversal
- Robust error handling using Verify333 assertions
Technical Implementation
- LinkedList: Managed head/tail pointers with node splicing logic
- HashTable: Used FNV hashing with separate chaining collision resolution
- Memory safety: Comprehensive Valgrind testing for leaks and errors
- Code quality: Followed Google C++ style guide with cpplint validation
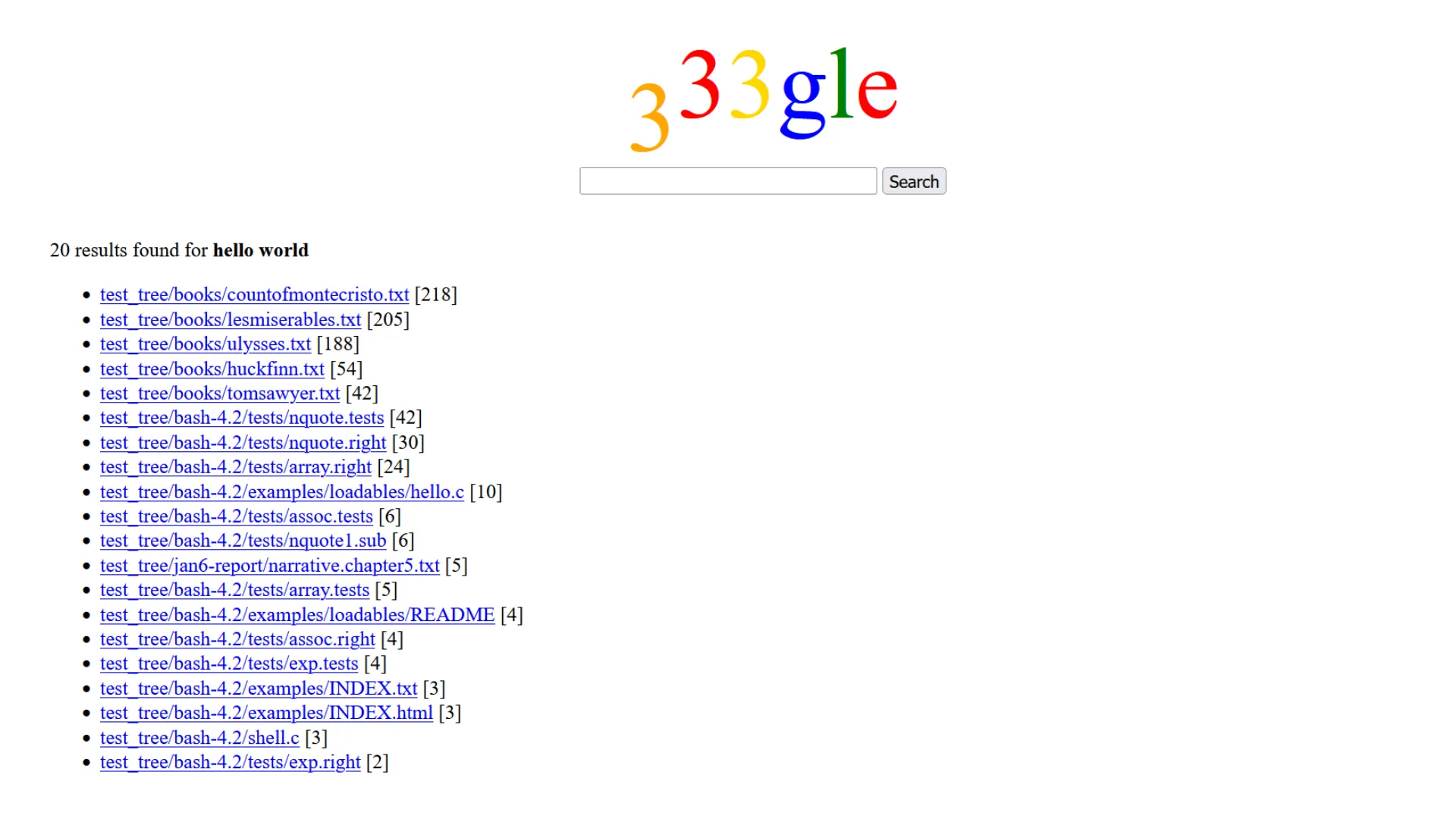
Homework 2: In-Memory Search Engine
Overview
Built a file system crawler, indexer, and query processor using HW1 data structures.
Components Implemented
Part A: File Parser
- Text file ingestion with memory-efficient string handling
- Word parsing using alphabetic character separation
- Position tracking with byte offset recording
- Case normalization converting all words to lowercase
Part B: Crawler and Indexer
- Recursive directory traversal with document ID assignment
- Inverted index construction mapping words → documents → positions
- Document table management for filename ↔ docID bidirectional lookup
Part C: Query Processor
- Multi-word query processing with result intersection
- Ranking algorithm based on term frequency summation
- Interactive shell with console-based user interface
Data Structures Used
- Document table: Dual hash tables for bidirectional lookup
- Inverted index: Nested hash tables (word → docID → positions)
- Position tracking: Linked lists maintaining sorted offsets
Homework 3: Disk-Based Search Engine
Overview
Extended HW2 search engine to persistent storage with architecture-neutral file format.
Components Implemented
Part A: Index Marshaller
- Big-endian serialization for cross-platform compatibility
- Complex file format with header, doctable, and index regions
- Checksum validation for data integrity verification
- Hierarchical data storage maintaining in-memory structure relationships
Part B: Index Reader
- C++ class hierarchy for file-based data structure access
- Efficient lookup algorithms for query processing
- Memory-mapped style access without full file loading
Part C: Multi-Index Search Shell
- Multiple index file support for distributed searching
- Rank aggregation across multiple corpora
- Interactive query interface with result merging
File Format Features
- Magic number identification (0xCAFEF00D)
- Embedded hash tables with bucket chaining
- Variable-length string storage
- Position list compression and sorting
Final Project: Web Server Security & Session Management
Security Features Implemented
Session Management
- Secure cookie generation with session tracking
- HMAC-SHA256 protection against cookie tampering
- Session validation with cryptographic verification
Authentication System
- Login page with credential processing
- Admin cookie minting for privileged access
- Plaintext authentication (noted as potential security concern)
Access Control
- Admin-only routes (
/quitquitquitendpoint protection) - Protected file access for
$(BASE_DIR)/admincontents - Role-based authorization using session cookies
Administrative Features
- Server logging of client requests and activities
- Admin dashboard with system overview
- Navigation system with role-appropriate links
Technical Implementation Details
- Cookie security: HMAC verification prevents unauthorized modifications
- Access enforcement: Session validation on protected endpoints
- User experience: Seamless navigation between public and admin areas
- Monitoring: Comprehensive request logging for administrative oversight